
Revolutionizing Research: Google’s AI Co-Scientist
Imagine a research partner that has read every scientific paper you have, tirelessly brainstorming new experiments around the clock. Google is trying to turn this vision into reality with a new AI system designed to act as a “co-scientist.”
This AI-powered assistant can sift through vast libraries of research, propose fresh hypotheses, and even outline experiment plans – all in collaboration with human researchers. Google’s latest tool, tested at Stanford University and Imperial College London, uses advanced reasoning to help scientists synthesize mountains of literature and generate novel ideas. The goal is to speed up scientific breakthroughs by making sense of information overload and suggesting insights a human might miss.
This “AI co-scientist,” as Google calls it, is not a physical robot in a lab, but a sophisticated software system. It is built on Google’s newest AI models (notably the Gemini 2.0 model) and mirrors the way scientists think – from brainstorming to critiquing ideas. Instead of just summarizing known facts or searching for papers, the system is meant to uncover original knowledge and propose genuinely new hypotheses based on existing evidence. In other words, it does not just find answers to questions – it helps invent new questions to ask.
Google and its AI unit DeepMind have prioritized science applications for AI, after demonstrating successes like AlphaFold, which used AI to solve the 50-year-old puzzle of protein folding. With the AI co-scientist, they hope to “accelerate the clock speed” of discoveries in fields from biomedicine to physics.
AI co-scientist (Google)
How an AI Co-Scientist Works
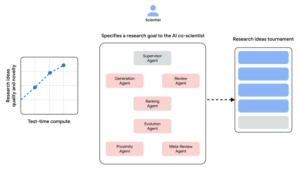
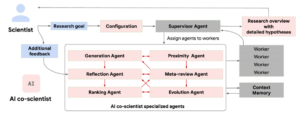
Under the hood, Google’s AI co-scientist is actually composed of multiple specialized AI programs – think of them as a team of super-fast research assistants, each with a specific role. These AI agents work together in a pipeline that mimics the scientific method: one generates ideas, others critique and refine them, and the best ideas are forwarded to the human scientist.
According to Google’s research team, here is how the process unfolds:
- Generation agent – mines relevant research and synthesizes existing findings to propose new avenues or hypotheses.
- Reflection agent – acts as a peer reviewer, checking the accuracy, quality, and novelty of the proposed hypotheses and weeding out flawed ideas.
- Ranking agent – conducts a “tournament” of ideas, effectively having the hypotheses compete in simulated debates, and then ranks them based on which seem most promising.
- Proximity agent – groups similar hypotheses together and eliminates duplicates so the researcher is not reviewing repetitive ideas.
- Evolution agent – takes the top-ranked hypotheses and refines them further, using analogies or simplifying concepts for clarity to improve the proposals.
- Meta-review agent – finally compiles the best ideas into a coherent research proposal or overview for the human scientist to review.
Crucially, the human scientist remains in the loop at every stage. The AI co-scientist does not work in isolation or make final decisions on its own. Researchers begin by feeding in a research goal or question in natural language – for example, a goal to find new strategies to treat a certain disease – along with any relevant constraints or initial ideas they have. The AI system then goes through the cycle above to produce suggestions. The scientist can provide feedback or adjust parameters, and the AI will iterate again.
Google built the system to be “purpose-built for collaboration,” meaning scientists can insert their own seed ideas or critiques during the AI’s process. The AI can even use external tools like web search and other specialized models to double-check facts or gather data as it works, ensuring its hypotheses are grounded in up-to-date information.
AI co-scientist agents (Google)
A Faster Path to Breakthroughs: Google’s AI Co-Scientist in Action
By outsourcing some of the drudge work of research – exhaustive literature reviews and initial brainstorming – to an unflagging machine, scientists hope to dramatically speed up discovery. The AI co-scientist can read far more papers than any human, and it never runs out of fresh combinations of ideas to try.
“It has the potential to accelerate scientists’ efforts to address grand challenges in science and medicine,” the project’s researchers wrote in the paper. Early results are encouraging. In one trial focusing on liver fibrosis (scarring of the liver), Google reported that every approach the AI co-scientist suggested showed promising ability to inhibit drivers of the disease. In fact, the AI’s recommendations in that experiment were not shots in the dark – they aligned with what experts consider plausible interventions.
Moreover, the system demonstrated an ability to improve upon human-devised solutions over time. According to Google, the AI kept refining and optimizing solutions that experts had initially proposed, indicating it can learn and add incremental value beyond human expertise with each iteration.
Another remarkable test involved the thorny problem of antibiotic resistance. Researchers tasked the AI with explaining how a certain genetic element helps bacteria spread their drug-resistant traits. Unbeknownst to the AI, a separate scientific team (in an as-yet unpublished study) had already discovered the mechanism. The AI was given only basic background information and a couple of relevant papers, then left to its own devices. Within two days, it arrived at the same hypothesis the human scientists had.
“This finding was experimentally validated in the independent research study, which was unknown to the co-scientist during hypothesis generation,” the authors noted. In other words, the AI managed to rediscover a key insight on its own, showing it can connect dots in a way that rivals human intuition – at least in cases where ample data exists.
The implications of such speed and cross-disciplinary reach are huge. Breakthroughs often happen when insights from different fields collide, but no single person can be an expert in everything. An AI that has absorbed knowledge across genetics, chemistry, medicine, and more could propose ideas that human specialists might overlook. Google’s DeepMind unit has already proven how transformative AI in science can be with AlphaFold, which predicted the 3D structures of proteins and was hailed as a major leap forward for biology. That achievement, which sped up drug discovery and vaccine development, even earned DeepMind’s team a share of science’s highest honors (including recognition tied to the Nobel Prize).
The new AI co-scientist aims to bring similar leaps to everyday research brainstorming. While the first applications have been in biomedicine, the system could in principle be applied to any scientific domain – from physics to environmental science – since the method of generating and vetting hypotheses is discipline-agnostic. Researchers might use it to hunt for novel materials, explore climate solutions, or discover new mathematical theorems. In each case, the promise is the same: a faster path from question to insight, potentially compressing years of trial-and-error into a much shorter timeframe.
-
What is Google’s new AI "Co-Scientist"?
Google’s new AI "Co-Scientist" is a machine learning model developed by Google Research to assist scientists in accelerating the pace of scientific discovery. -
How does the "Co-Scientist" AI work?
The "Co-Scientist" AI works by analyzing large amounts of scientific research data to identify patterns, connections, and potential areas for further exploration. It can generate hypotheses and suggest experiments for scientists to validate. -
Can the "Co-Scientist" AI replace human scientists?
No, the "Co-Scientist" AI is designed to complement and assist human scientists, not replace them. It can help researchers make new discoveries faster and more efficiently by processing and analyzing data at a much larger scale than is possible for humans alone. -
How accurate is the "Co-Scientist" AI in generating hypotheses?
The accuracy of the "Co-Scientist" AI in generating hypotheses depends on the quality and quantity of data it is trained on. Google Research has tested the AI using various datasets and found promising results in terms of the accuracy of its hypotheses and suggestions. - How can scientists access and use the "Co-Scientist" AI?
Scientists can access and use the "Co-Scientist" AI through Google Cloud AI Platform, where they can upload their datasets and research questions for the AI to analyze. Google offers training and support to help scientists effectively utilize the AI in their research projects.






